AlphaFind: a new compass in the world of proteins
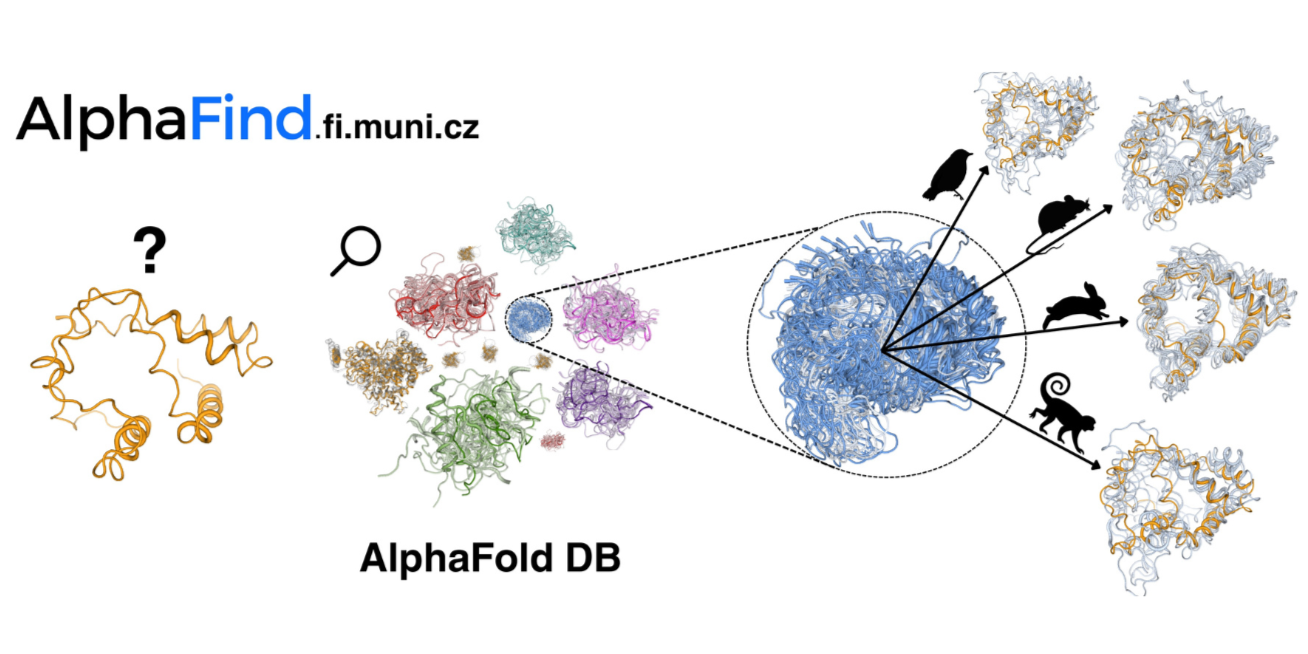
A research team from Masaryk University (MU) has introduced a new bioinformatics innovation - AlphaFind, a web-based tool designed to simplify the search for proteins in the AlphaFold database (AlphaFold DB). It promises faster orientation in large-scale data, the possibility of 3D visualizations, as well as general accessibility and user-friendliness.
Proteins are the basic building blocks of our cells and play a key role in their functioning. Individual proteins differ from each other primarily by the order of the amino acids they contain. AlphaFold DB works with more than 200 million protein samples, providing scientists with a "library" from which to borrow specific proteins for their research. Based on the sequence of amino acids, the database can use artificial intelligence to predict the 3D structure of individual proteins, which helps to understand their biological functions and develop effective methods to prevent or treat diseases, for instance. However, the comprehensiveness of the entire database places demands on the processing of large amounts of data to search for specific samples. This is where AlphaFind, a new tool from Masaryk University, comes in.
"The main goal of AlphaFind is to provide a fast, scalable and user-friendly platform for searching and comparing protein structures within the AlphaFold DB. Unlike traditional tools that often struggle with large datasets, AlphaFind focuses on tertiary protein structures and uses advanced machine learning models to efficiently identify candidate proteins and then compare their 3D structures in detail," explains Vlastislav Dohnal from the Department of Machine Learning and Data Processing, Faculty of Computer Science, MU, one of the authors of the tool.
AlphaFind promises several key benefits. With a new approach to indexing that significantly reduces the size of data from approximately 23 terabytes to 20 gigabytes, it efficiently processes the entire database. The search engine provides fast search results, typically returning the 50 most similar structures in about 7 seconds. The web application itself is designed to be easy to use, does not require registration and supports various input formats such as UniProt IDs, PDB IDs and Gene Symbols. It also includes tools for 3D visualization of protein superpositions, allowing for immediate analysis of structural similarities.
The development of AlphaFind was led by four units at MU. The core of the application and its infrastructure were developed by the CERIT-SC centre of the Institute of Computer Science, which also coordinated the whole collaboration. The structure similarity search mechanism is based on the research of the Intelligent Systems for Complex Data group of the Faculty of Informatics. The researchers from the Biological Data Management and Analysis Core Facility from CEITEC and the National Centre for Biomolecular Research of the Faculty of Science then evaluated quality and usability from a structural biology perspective. AlphaFind is thus a shining example of synergy at MU.
The entire team has recently published their results in the journal Nucleic Acids Research, where they presented the new tool and offered it for wider use to the entire scientific community. The full article can be found here: https://doi.org/10.1093/nar/gkae397.
AlphaFind is available online and free of charge at https://alphafind.fi.muni.cz. The user guide and source code are available on GitHub.
AlphaFind
The Protein Data Bank, a database of existing proteins available to the scientific community for related research, has been in development since the 1970s. Then in 2018, the DeepMind company built the AlphaFold tool on top of it, which today contains over 200 million protein samples, mostly of human origin, but also of other organisms relevant for genetic research. Using AI, the database can then use the amino acid sequence to predict the 3D structure of different types of proteins, which is key to understanding their biological functions. These simplified models of proteins then help, for example, in the development of new drugs, where we study the effect of these drugs on individual parts of proteins and can then target treatments more effectively. On May 8, 2024, the developers introduced a new version of AlphaFold3 that can also model the interaction of proteins with other molecules, again significantly advancing research opportunities.
Intelligent Systems for Complex Data Research Group
We are a team of researchers at Masaryk University in Brno, Czech Republic, specializing in complex data analysis. As part of the Laboratory of Data Intensive Systems and Applications at FI MU and in close collaboration with the CERIT-SC centre, we aim to discover patterns within vast amounts of complex data. We tackle unique challenges ranging from exploring patterns in images to the intricate analysis of complex biological structures such as proteins. Our ambition is to redefine the boundaries of effective and efficient processing of large datasets by leveraging our proficiency in machine learning, data mining, and clustering techniques.
- Attachments
{kind=link}